My AI Coding Guide for 2026: Workflow, Architecture, and CI Gates
An operating manual for AI coding agents in 2026: the planning workflow, deep-module architecture, quality gates, and skills I use to turn sloppy AI output into shippable code.
By Victor Saisse · · 20 min read
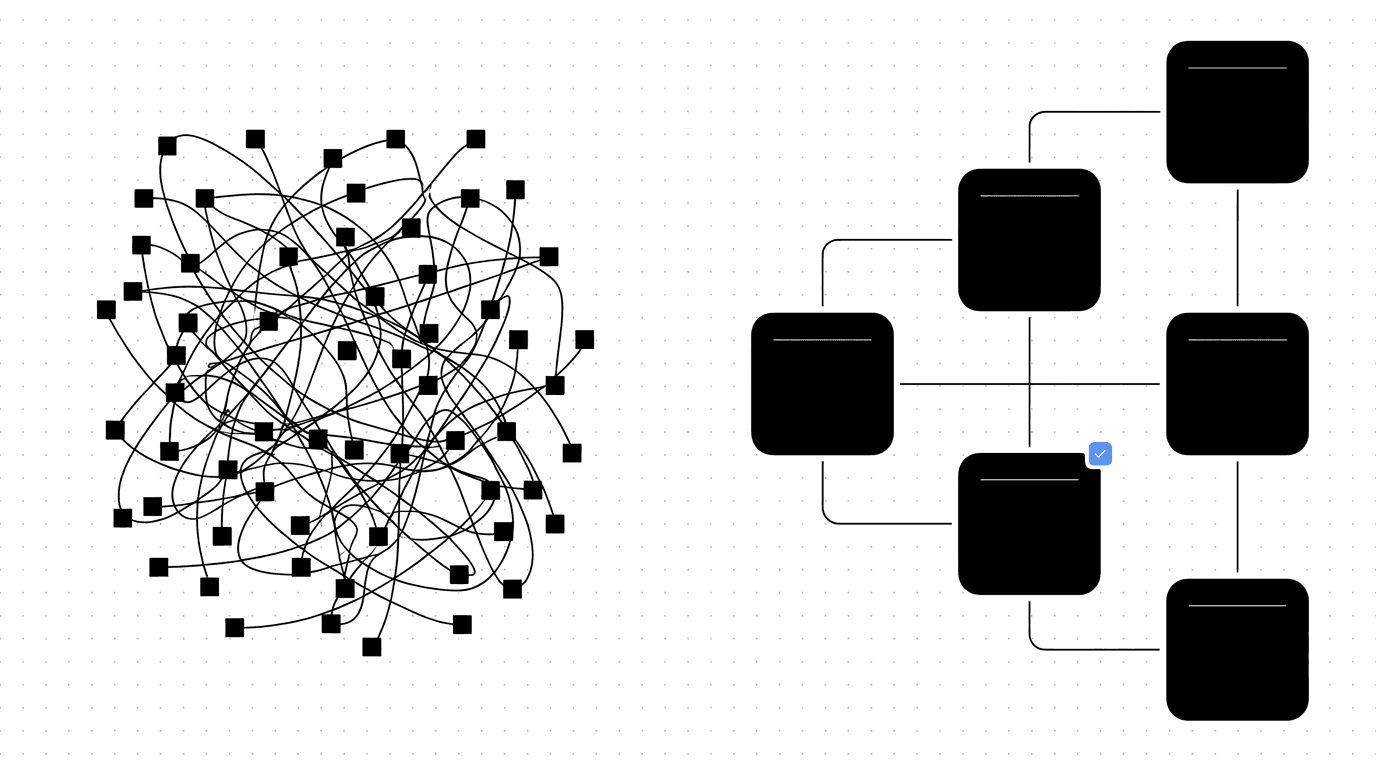
For about a year now, most of my dev loop has run alongside AI agents: multiple Claude Code sessions in parallel, orchestrated through Conductor, wired into Slack with persistent memory. When the process is good, the output is good. When the process is sloppy, the agents amplify the sloppiness, fast.
I expected the model to be the bottleneck. It almost never is. The bottleneck is the codebase, the workflow, and whatever quality gates aren't there to catch what the agent missed. This guide is the boil-down: every recurring failure mode I've hit in 12 months, paired with the practice that prevents it.
I write it as an operating manual for the agent itself. That's the format that ends up in the root of every project I touch: a CLAUDE.md (or AGENTS.md) the agent reads on session one, every session.
For your AI agent: This document is your operating manual. Read it fully before touching any code. When the user points you at an existing codebase, run the Audit Checklist at the bottom first. When starting a new project, run the Bootstrap Checklist instead.
Core Principles (read these first)
- You have no memory. Every session you start is a new starter joining the team. The codebase, not the prompt, is what teaches you. If the codebase is messy, your output will be messy.
- Don't jump to code. For anything non-trivial, plan first, reach shared understanding, write a PRD, break it into issues, then implement.
- Process > cleverness. Strict, repeatable processes produce better code than smart improvisation.
- Treat the codebase like it has new starters joining every day, because it does. You are those new starters.
- Tests and CI are the real review. Humans can't read 10,000 lines of AI-generated code per day. Static analysis, coverage, mutation testing, and architectural checks are the real quality gate.
- Deep modules over shallow modules. Few large modules with simple interfaces beat many tiny modules with tangled relationships.
Part 1: The Workflow (Plan → Implement → Verify)
Every non-trivial change follows this four-step loop. Do not skip steps.
Step 1: Grill Me (reach shared understanding)
Before any plan or PRD, the AI must interview the user about the change. Walk down each branch of the design tree, resolving dependencies one decision at a time. If a question can be answered by exploring the codebase, explore the codebase instead of asking.
Trigger phrase the user will use: "grill me on X" or "let's design X"
What you do:
- Explore the relevant parts of the codebase first (don't ask questions you can answer yourself).
- Ask questions one branch at a time. Don't dump 10 questions at once.
- Cover: where does it live? UI/API shape? lifecycle? edge cases? error states? what existing modules does it touch?
- Keep going until you have a complete mental model. Expect 10-30+ questions for a real feature.
- End with a summary the user must confirm.
Example skill file (.claude/skills/grill-me.md):
---
name: grill-me
description: Use when the user wants to design a feature before writing code. Triggers on "grill me", "let's design", "plan this with me".
---
Interview the user relentlessly about every aspect of this plan until you reach
a shared understanding. Walk down each branch of the design tree, resolving
dependencies between decisions one by one. If a question can be answered by
exploring the codebase, explore the codebase instead of asking.
Ask one question at a time. Wait for the answer before moving to the next.
End with a written summary for the user to confirm.Step 2: Write the PRD
Once shared understanding exists, write a Product Requirements Document. The PRD is the destination, not the journey. Implementation details should be light enough to stay durable as code evolves.
PRD template:
# [Feature Name]
## Problem Statement
What is broken or missing today? One paragraph.
## Solution Overview
The destination in 3-5 sentences.
## User Stories
- As a [role], I want to [action], so that [outcome].
- (Multiple stories; describe behavior in plain language.)
## Acceptance Criteria
- [ ] Concrete, testable conditions
- [ ] Each one verifiable by a test or manual check
## Implementation Decisions (light)
- Key architectural choices
- Modules affected
- New interfaces being introduced
- NOT step-by-step instructions
## Out of Scope
What we're explicitly NOT doing.Submit the PRD as a GitHub issue (or save to docs/prds/ if no GitHub).
Step 3: PRD → Issues (vertical slices)
Break the PRD into independently grabable issues. Each issue is a thin vertical slice that cuts through all integration layers, not a horizontal slice of one layer (the "tracer bullet" approach).
Rules:
- Order issues so unknown unknowns surface first. If you're integrating with something new, do that integration in issue #1.
- Each issue references the parent PRD.
- Establish blocking relationships explicitly (
Blocked by #123). - Each issue references the user stories from the PRD it satisfies.
Anti-pattern (horizontal slicing):
Issue 1: Build all the database schemas
Issue 2: Build all the API endpoints
Issue 3: Build all the UINothing works until everything works. You won't find integration problems until the end.
Correct pattern (vertical slicing):
Issue 1: End-to-end flow for the simplest case (DB + API + minimal UI)
Issue 2: Add filtering (DB query + API param + UI control)
Issue 3: Add sorting (same shape)
Issue 4: Polish + edge casesStep 4: Implement with TDD (Red → Green → Refactor)
For every issue, follow this loop:
- Confirm interface changes with the user. If you're modifying or adding an exported function/class/component, surface that decision before writing code. Interfaces are the seams of the codebase; they require taste.
- Confirm which behaviors to test. List them as bullet points before writing tests.
- Write one failing test. Run it. Confirm it fails for the right reason.
- Write the minimum code to make it pass. Run the test. Confirm green.
- Look for refactor candidates. Be honest. LLMs are reluctant to refactor their own code; force yourself to.
- Repeat until all behaviors are covered.
Example skill file (.claude/skills/tdd.md):
---
name: tdd
description: Use when implementing a feature or fixing a bug. Enforces red-green-refactor.
---
Follow this exact loop:
1. Confirm with the user what interface changes are needed (exported functions,
types, components). Wait for approval before continuing.
2. List the behaviors to test as bullet points. Wait for approval.
3. For each behavior, in order:
a. Write ONE failing test. Run it. Confirm it fails.
b. Write the minimum code to pass. Run it. Confirm green.
c. Pause and look for refactor candidates. Refactor if needed.
4. Do not write code without a failing test demanding it.
5. Do not move to the next behavior until the current one is green.Part 2: Codebase Architecture (Deep Modules)
Your codebase is the most important context window the AI has. Structure it badly and no prompt rescues it. Structure it well and even a mediocre prompt produces decent code.
The rule: deep modules with simple interfaces
Bad (shallow modules):
src/
utils/
formatDate.ts ← 8 lines
formatCurrency.ts ← 6 lines
capitalizeFirst.ts ← 3 lines
parseUserInput.ts ← 12 lines
validateEmail.ts ← 9 lines
... 40 more files
components/
Button.tsx
ButtonIcon.tsx
ButtonGroup.tsx
... 80 more filesTons of files. No groupings. The AI sees a flat soup of modules that can all import each other. Hard to navigate, hard to test, hard to keep in your head.
Good (deep modules):
src/
features/
video-editor/
index.ts ← public interface (types + exports)
README.md ← what this module does
engine.ts ← implementation (private)
timeline.ts ← implementation (private)
__tests__/
thumbnail-editor/
index.ts
README.md
...
auth/
index.ts
README.md
...
shared/
ui/
index.ts ← only Button, Input, Modal exported
...Each feature is a "deep module": lots of implementation behind a small, controlled interface. Other features only import from index.ts. Internal files are invisible to the rest of the codebase.
Why this matters for AI
- Progressive disclosure: AI reads
index.tsand the README first. It understands what the module does without reading the implementation. - Gray-box trust: If tests cover the interface, the AI doesn't need to look inside. It can treat the module as a black box.
- Smaller mental map: Instead of holding 200 modules in context, the AI holds 8 features. Easier to plan, easier to change.
- Clear test boundaries: Tests live at the interface. No ambiguity about what to mock.
Enforcing it
Add an ESLint rule (or equivalent for your language) that bans cross-feature imports of anything except index.ts:
// .eslintrc: example for TypeScript
{
"rules": {
"no-restricted-imports": ["error", {
"patterns": [{
"group": ["**/features/*/!(index)", "**/features/*/**"],
"message": "Import from the feature's index.ts only."
}]
}]
}
}When to refactor toward deep modules
Run the Improve Architecture check periodically (weekly, or after a feature surge):
- Explore the codebase as a fresh starter would. Where does understanding one concept require bouncing between many small files?
- Where have pure functions been extracted just for testability, but the real bugs hide in how they're called?
- Where are tightly coupled modules creating integration risk in the seams?
- List candidates as a numbered list. Pick one with the user.
- Spawn 2-3 parallel design sketches with radically different interfaces for the deepened module. Compare. Pick (or hybrid).
- File a refactor RFC as a GitHub issue. Then run the PRD → Issues flow on it.
Part 3: Quality Gates in CI (the real code review)
You can't read every line the AI produces. So make CI do the reviewing for you. Static analysis, coverage, mutation testing, and bug-class detectors are the only review that scales when you're shipping multiple agent sessions a day.
These are the gates every PR must pass. Add them to your CI pipeline (GitHub Actions, GitLab CI, etc.) and configure them to block merge on failure.
Gate 1: Cyclomatic complexity
Counts paths through a function (every if, else, ternary, &&, etc. adds a path). LLMs love writing 120-line functions with 15 nested ifs. Block them.
Threshold: fail if any function exceeds CCN of 15 (some teams use 10).
Tools:
- JS/TS:
eslintwithcomplexityrule, orlizard - Python:
radon cc -ncorlizard - Go:
gocyclo - Java/Kotlin/C#: SonarQube
- Polyglot:
lizard(works on most languages)
# Example CI step
- name: Cyclomatic complexity
run: lizard --CCN 15 --warnings_only src/Gate 2: Test coverage
Threshold: typical baseline is 80% line coverage on changed files. Tune to your context.
Important: Coverage alone is a weak signal. A test that calls a function without asserting anything passes coverage. Pair it with mutation testing (next gate).
Gate 3: Mutation testing
Mutation testing flips operators in your code (> becomes <, + becomes -, true becomes false) and checks if your tests catch the change. If a mutation survives, your tests are not actually testing that code path.
Threshold: start at 60% mutation score, raise as the codebase matures.
Tools:
- Python:
mutmutormutpy - JS/TS:
stryker - Java:
pitest - Go:
go-mutesting
# Python example
pip install mutmut
mutmut run
mutmut results # shows surviving mutants; these are your bugsGate 4: Module size
Block god files. LLMs love appending to existing files instead of creating new modules.
Threshold: 300 lines per file (excluding tests, generated code, JSON fixtures).
# Simple check
find src -name "*.ts" -exec wc -l {} + | awk '$1 > 300 { print; fail=1 } END { exit fail }'Gate 5: Dependency structure
Detect circular imports and architectural violations (e.g., a controller reaching into a database layer directly, an implementation module importing another implementation module instead of going through its public API).
Tools:
- JS/TS:
madge --circular src/, ordependency-cruiser(lets you encode rules like "controllers cannot import models") - Python:
pydepsorimport-linter(rules-based) - Java: ArchUnit
- Go:
go-cleanarch
Example dependency-cruiser rule:
{
name: 'no-cross-feature-implementation',
severity: 'error',
from: { path: '^src/features/([^/]+)/' },
to: { path: '^src/features/(?!\\1)/[^/]+/(?!index)' }
}Gate 6: Security scans
- SAST:
semgrep(catches injection, hardcoded secrets, unsafe deserialization). - Dependency CVEs:
npm audit,pip-audit,cargo audit, GitHub Dependabot. - Secret scan:
gitleaksortrufflehogon every commit. - Pin dependency versions (lockfiles + exact versions for critical deps); supply-chain attacks are real.
Gate 7: Bug-class detectors
Three bug classes the AI generates constantly. Catch them automatically.
N+1 query detector
LLMs love for item in items: db.query(item.id). Works fine in dev with 10 rows. Dies in prod at 10,000.
Plant a middleware that counts queries per request. Threshold: >15 queries per request → log + fail the test.
# Django/SQLAlchemy/Prisma: plant a hook
QUERY_THRESHOLD = 15
def query_counter_middleware(request):
counter = QueryCounter()
with counter:
response = next_middleware(request)
if counter.count > QUERY_THRESHOLD:
logger.warning(f"N+1 risk: {counter.count} queries on {request.path}")
if IS_TEST_ENV:
raise AssertionError(f"Too many queries: {counter.count}")
return responseRace condition / property-based tests
LLMs sprinkle await without thinking about two requests arriving simultaneously. Result: negative balances, double bookings, deadlocks.
Property-based testing bombards a function with thousands of random inputs (and concurrent calls) and checks an invariant.
# Python: hypothesis
from hypothesis import given, strategies as st
@given(st.lists(st.integers(min_value=1)))
def test_balance_never_negative(transactions):
account = Account(balance=0)
for amount in transactions:
account.deposit(amount)
for amount in transactions:
account.withdraw(amount)
assert account.balance >= 0 # invariant// TypeScript: fast-check
import fc from 'fast-check';
fc.assert(
fc.property(fc.array(fc.integer({ min: 1 })), (txs) => {
const acc = new Account();
txs.forEach(t => acc.deposit(t));
txs.forEach(t => acc.withdraw(t));
return acc.balance >= 0;
})
);Memory leak detection
A queue that never drains, a cache without TTL, an event listener never removed. Doesn't show up in dev; kills prod over hours.
- Run a soak test in CI: hit the service for 10 minutes, watch memory. Fail if RSS grows >X%.
- Profile with
py-spy(Python), Chrome DevTools heap snapshots (browser/Node),pprof(Go). - Take heap snapshots at start and end. Diff them. Anything that's still allocated and unreferenced is a leak.
Gate 8: Failure-mode tests
What happens if the database drops mid-request? The AI didn't think about it. You have to.
For every external dependency (DB, queue, third-party API, file system), have at least one test that simulates failure: timeout, 500, network drop, malformed response. Tools: toxiproxy, wiremock, or simple mock failures.
Part 4: Skills (reusable instruction sets)
Skills are short markdown files the AI loads on demand. They encode the recurring processes you don't want to re-explain every session. Keep them in .claude/skills/ (or your tool's equivalent) so the agent can find them.
Rule of thumb: if you've explained the same thing to the AI three times, write it as a skill.
Skill design rules
- Short is fine. The grill-me skill is three sentences. Length isn't quality; precision is.
- One job per skill. Don't combine "design + implement + review" into one skill.
- Trigger description matters most. The
descriptionfield is what makes the AI auto-invoke the skill. Be specific about when it applies. - Test the trigger. After writing a skill, ask the AI a question that should invoke it. If it doesn't, rewrite the description.
- Chain skills. A copywriting skill should end with
now run the humanizer skill. A PRD skill should end withnow run the PRD-to-issues skill.
Recommended skill set for this guide
Drop these into .claude/skills/:
| Skill file | Purpose |
|---|---|
grill-me.md | Force shared understanding before planning |
write-prd.md | Turn shared understanding into a PRD doc |
prd-to-issues.md | Break PRD into vertical-slice GitHub issues |
tdd.md | Red-green-refactor implementation loop |
improve-architecture.md | Periodic codebase health check |
pre-commit.md | Run all CI gates locally before committing |
The full text for grill-me and tdd is above. Generate the others by feeding this guide to your AI and asking it to produce them in the same style.
Part 5: Things the AI Must NEVER Do
Hard rules. Put these in your CLAUDE.md / AGENTS.md / project-root system prompt.
- Never skip the grill-me phase for non-trivial work. A bug fix in one function is fine. A new feature, a refactor, or anything touching >2 modules requires grill-me first.
- Never write code without a failing test (when TDD is enabled). No exceptions. If you "just want to try something," write a test first.
- Never add a new file in a top-level
utils/orhelpers/directory. Find the feature module it belongs in, or create a new feature module. - Never import from another feature's internals. Only
import { X } from 'features/foo'. Neverimport { X } from 'features/foo/internal/thing'. - Never write a function longer than ~50 lines. If you're heading there, decompose first.
- Never silently catch errors. No
catch (e) {}. Either handle the error meaningfully or let it propagate. - Never commit secrets. Use
.env, never check it in. Pre-commit hook runsgitleaks. - Never bump dependency versions casually. Pin them. Bumps go through their own PR with a clear reason.
- Never disable a test to "fix" CI. If a test is wrong, fix the test. If it's flaky, fix the flake. Skipping is the last resort and requires an issue link.
- Never write more than ~200 lines of code without running tests. Run them as you go.
Part 6: CLAUDE.md template (drop this in your repo root)
# Project Conventions
## Architecture
- Feature-first folder structure under `src/features/`.
- Each feature has: `index.ts` (public API), `README.md` (purpose), `__tests__/`.
- Cross-feature imports are restricted to `index.ts` only (enforced by ESLint).
## Workflow
For any non-trivial change:
1. Run the `grill-me` skill before planning.
2. Run the `write-prd` skill once shared understanding is reached.
3. Run the `prd-to-issues` skill to break the PRD into vertical slices.
4. Use the `tdd` skill to implement each issue.
## Quality Gates (must pass before merge)
- Cyclomatic complexity < 15 per function
- Test coverage > 80% on changed files
- Mutation score > 60%
- No file > 300 lines (excluding tests/fixtures)
- No circular dependencies
- `semgrep`, `gitleaks`, `npm audit` all clean
## Hard Rules
[Copy the 10 rules from Part 5 here.]
## Tech Stack
[List languages, frameworks, key libraries, deployment target.]
## Local Commands
- `npm test`: run unit tests
- `npm run test:mutate`: mutation testing
- `npm run lint`: ESLint + complexity check
- `npm run check:deps`: dependency-cruiser
- `npm run check:all`: runs everything aboveAudit Checklist: for an EXISTING codebase
Run this when the user says "apply this guide to my codebase." Work through each item, report findings, fix incrementally; do not try to do all of it in one PR.
- Map the codebase. Produce a tree showing top-level structure. Identify natural feature groupings vs. shallow-module sprawl.
- Find god files. List every file > 300 lines. Propose splits.
- Find the
utils/andhelpers/graveyards. List functions in them. For each, identify which feature it actually belongs to. - Detect circular imports. Run
madge --circular(or equivalent). List them. - Measure cyclomatic complexity. Run
lizard. List every function over 15. Propose decomposition for the worst 10. - Measure current test coverage. Run the tool. Report by directory. Identify the most under-tested feature.
- Run mutation testing on the most critical module (auth, payments, anything that handles money or PII). Report surviving mutants.
- Scan for N+1 risks. Search for loops containing DB calls (
for ... in ... { await db. }patterns). List candidates. - Scan for missing failure-mode tests. For each external dependency, check if at least one test simulates failure.
- Check security baseline. Run
semgrep,gitleaks,npm audit(or equivalents). Report findings. - Inventory existing CLAUDE.md / AGENTS.md. If absent, create one from the template in Part 6.
- Inventory existing skills. List anything in
.claude/skills/. Identify gaps. - Produce a prioritized backlog. Order findings by: (1) security, (2) bug-class risks (N+1, race, leaks), (3) architectural debt, (4) coverage gaps. Submit as GitHub issues using the PRD-to-issues flow.
- Set up CI gates incrementally. Start with security scans (zero false positives), then complexity, then coverage, then mutation. Each gate enabled in its own PR.
- Pick one shallow-module cluster and deepen it as a worked example. Use the
improve-architectureflow.
Bootstrap Checklist: for a NEW project
Run this when the user says "start a new project with this guide."
- Confirm scope with grill-me. Don't pick a stack until you understand the project.
- Choose stack with intent. Prefer languages/frameworks with strong static analysis (TypeScript, Rust, Go, Kotlin, Python with
mypy --strict). - Initialize folder structure as
src/features/with one example feature scaffolded (index.ts,README.md, one test file). - Write
CLAUDE.mdfrom the Part 6 template, customized to the chosen stack. - Drop in
.claude/skills/with at minimum:grill-me.md,write-prd.md,prd-to-issues.md,tdd.md,improve-architecture.md. - Configure linting with the cross-feature-import rule.
- Configure complexity check in CI (lizard or eslint-complexity).
- Configure test runner + coverage with an 80% threshold (start lower if needed and raise).
- Configure mutation testing (stryker / mutmut / pitest). Start with a 50% threshold.
- Configure dependency check (madge / dependency-cruiser / import-linter).
- Configure security scans (semgrep + gitleaks + dependency CVE scanner).
- Configure pre-commit hook that runs lint + complexity + secret scan locally.
- Configure CI pipeline that blocks merge on any gate failure.
- Configure failure-mode test harness (toxiproxy or wiremock if there will be external services).
- Write the first feature using the full Plan → Implement → Verify loop as a working example for future sessions.
- Open a
docs/prds/folder for storing PRDs. - Open a
docs/decisions/folder for ADRs (architecture decision records). Every non-obvious choice gets one.
Appendix: Quick Reference Card
For ANY change:
1. grill-me (until shared understanding)
2. write-prd (the destination)
3. prd-to-issues (vertical slices, ordered by unknown unknowns)
4. tdd loop per issue (red → green → refactor)
For the codebase:
- Deep modules, simple interfaces
- features/<name>/{index.ts, README.md, __tests__/}
- Cross-feature imports ONLY via index.ts
For CI gates (all blocking):
- Cyclomatic complexity < 15
- Coverage > 80%
- Mutation score > 60%
- File size < 300 lines
- No circular deps
- Security scans clean
- N+1 detector + property tests + leak detection
For trust:
- Tests are the contract
- CI is the review
- You don't read 10k lines of AI code per day; you read the gatesTake this with you
If you want to drop this whole guide into your own project, grab the markdown:
Download the full markdownDrop it in the root of your repo as CLAUDE.md (or AGENTS.md, or whatever your tool reads), and start with the Bootstrap Checklist for new projects or the Audit Checklist for an existing one.
This guide is the operating manual. When in doubt, re-read the Core Principles. When the user disagrees with the guide, the user wins, but ask them to tell you why so the guide can improve.
Next post: Welcome to My Portfolio
Questions or want to work together? Email saissevictor@gmail.com or find me on LinkedIn.